
Author: Ambika Sharma, Founder and Chief Strategist, Pulp Strategy
Updated December 2025
Executive Overview
AI search has overtaken traditional search engines as the first layer of enterprise discovery, trust formation, and category definition. As of 2025, platforms such as ChatGPT, Gemini, Claude, and Perplexity are shaping enterprise demand by relying on recall rather than ranking. This shift marks a structural change in how technology firms achieve visibility, influence decision making, and protect reputation. AI search has overtaken traditional search engines as the first layer of enterprise discovery, trust formation, and category definition. As of 2025, platforms such as ChatGPT, Gemini, Claude, and Perplexity are shaping enterprise demand by relying on recall rather than ranking. This shift marks a structural change in how technology firms achieve visibility, influence decision making, and protect reputation.
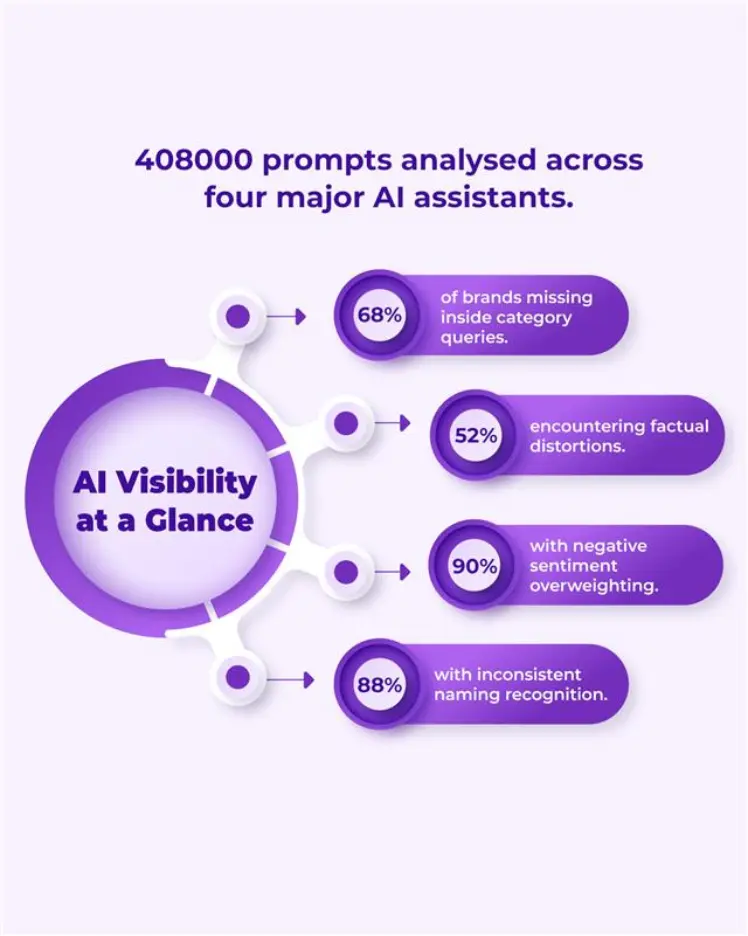
This article draws entirely from Pulp Strategy’s GEO Benchmark Index 2025, powered by NeuroRank™. The research includes 70 full‑spectrum GEO audits, 350 cross‑industry brands, 408000 real prompt simulations, and more than 60 anonymised CMO and CXO interviews. The findings reveal quantifiable disruption: 68 percent of brands are invisible in category answers, 52 percent face factual inaccuracies, 90 percent encounter negative sentiment overweighting, and 88 percent experience inconsistent naming or recognition across AI models. These findings represent the first large‑scale empirical map of how AI search interprets brand authority.
For CMOs, CROs, and P&L decision makers, the implications are direct. AI‑era visibility now determines whether a brand enters the consideration set at all. The research confirms that traditional SEO does not translate into AI recall. NeuroRank™ provides the measurement, remediation, and governance system required to protect brand accuracy, strengthen trust signals, and restore category presence.
Download the GEO Benchmark Index 2025 to review full cross‑industry findings from the research.
Request a NeuroRank™ AI Visibility Audit to benchmark your brand’s inclusion, trust signals, and hallucination exposure
Why This Research Matters to Enterprise Decision Makers
Enterprise CMOs, CROs, and budget owners are under pressure to defend pipeline visibility, protect brand accuracy, and maintain competitive positioning in a market where AI assistants have become the first interpreters of category strength. The GEO Benchmark Index 2025 quantifies this shift using evidence, not assumptions. It provides decision makers with:
- A validated map of where their brand stands inside AI answers.
- A benchmark against 350 peers across industries.
- A visibility and trust risk framework tied directly to revenue impact.
- A blueprint for protecting category authority in an AI‑first buying world.
This alignment between research evidence and executive priorities is what drives reading depth, research downloads, and interest in NeuroRank™.
Download the GEO Benchmark Index 2025 to examine full sector‑specific findings.
Request a NeuroRank™ AI Visibility Audit to understand where your brand stands today.
The Highlights
Why AI Search Is Rewiring Enterprise Demand
Enterprise buying has entered a new era where generative AI assistants answer technical, commercial, and strategic queries before a human‑curated source is ever visited. This shift is measurable. The GEO Benchmark Index 2025 confirms through 60 anonymised CMO and CXO interviews that AI assistants have become a primary tool for early‑stage vendor discovery, market understanding, and credibility validation in enterprise buying journeys.
Instead of reading a website or downloading a whitepaper, the enterprise buyer now asks:
- What are the best cloud platforms for regulated industries?
- Which cybersecurity vendors have the strongest AI‑driven threat detection?
- Top enterprise integrations for hybrid infrastructure environments?
If your brand is not cited inside these conversational answers, you are no longer in the consideration set.
This transition from search to recall defines the competitive landscape for enterprise tech firms. AI assistants are not discovery channels, they are the new decision engines. This unlocks a cross‑industry truth: whether you sell cloud solutions, financial products, diagnostic tools, or consumer appliances, your buyer now begins their journey inside an LLM, not a SERP.
How AI Assistants Shape Trust and Recall
Understanding how AI engines construct trust requires more than a high‑level ai overview. It demands clarity on how LLMs evaluate structured surfaces, citations, and semantic consistency. This is the foundation of effective ai mode optimisation and the core of AI‑era visibility.
LLMs do not interpret brands the way search engines do. They do not index every page or recognise SEO‑led signals. They rely on patterns, trust clusters, structured data, and semantic consistency.
The GEO Benchmark Index 2025 reveals that AI models construct trust based on four pillars:
- Structured machine‑readable content (schema, FAQs, knowledge graphs, citations).
- Cross‑ecosystem consistency across documentation, forums, and authoritative sources.
- Sentiment stability, with negativity disproportionately amplified.
- Recall frequency, driven by prompt patterns and training signals.
If any of these pillars are weak, the model either omits the brand or replaces it with competitors or generic alternatives.
What the Data Reveals from 408000 Prompt Simulations
Drawing from NeuroRank™’s multi‑model simulation engine:
- 68 percent of brands did not appear in AI‑generated shortlists within their own categories.
- 52 percent suffered factual distortions.
- 88 percent encountered cross‑lingual naming or recognition inconsistencies.
- 90 percent of consumer brands experienced negative sentiment overweighting.
These statistics highlight a structural visibility failure that cannot be solved by traditional SEO.
Brands lose demand not because they lack capability, but because models lack machine‑readable evidence.
Why Traditional SEO Fails in an AI‑First World
This shift also exposes the limits of search engine optimization, including its newer variations such as AI for SEO, AI and SEO, and emerging AI SEO tools or AI tools for SEO. Traditional optimisation cannot influence model‑level recall because artificial intelligence search engine optimization requires structured authority, not keyword density. Models do not interpret rankings through a google ai overview or search labs ai overview lens. They rely on factual stability and trust patterns.
In this environment, even advanced approaches like seo gpt, chatgpt seo, or broad generative ai overview tactics cannot compensate for missing or inconsistent machine‑readable signals. GEO and AIO (AI Optimization) become essential because they directly influence what models remember, surface, and recommend.
SEO was built for crawlers, not cognition. It optimises for indexing, ranking, and link authority. Large language models bypass this framework completely.
LLMs do not crawl. They recall.
They retrieve patterns and trusted narratives from:
- Structured data surfaces
- High‑authority third‑party ecosystems
- Consistent documentation
- Frequent co‑occurrence with validated concepts
A top‑ranked page holds no value if the model cannot interpret, structure, or trust the content. This creates the AI visibility paradox many enterprise CMOs face: highest SEO scores, lowest AI recall.
How Enterprise CMOs Are Responding
Across 60+ interview transcripts, CMOs express four urgent priorities:
- Reclaim visibility in commercial prompts.
- Repair hallucinations before they distort buyer perception.
- Engineer structured narratives that models can cite reliably.
- Build GEO governance as an enterprise AI capability, not a marketing experiment.
CMOs recognise that visibility, accuracy, and trust in AI answers directly influence pipeline and revenue. GEO has moved from a tactical experiment to a board‑aligned priority.
The NeuroRank™ Framework: How It Works and Why It Matters
NeuroRank™ is the GEO engine behind the Benchmark Index. Built specifically for AI‑era visibility, it provides CMOs, CROs, and P&L leaders with a structured, evidence-based system to diagnose, repair, and elevate brand presence inside AI-generated answers.
The Five-Part NeuroRank™ Framework
1. Model‑Level Visibility Mapping NeuroRank™ evaluates how consistently a brand is recalled across ChatGPT, Gemini, Claude, and Perplexity. This includes:
- Inclusion rate across commercial prompts
- Absence patterns in category and competitive queries
- Sentiment weighting and polarity shifts
- Cross-model inconsistency and identity drift
This gives enterprises the first quantitative visibility score in an AI-first world.
2. Hallucination and Distortion Diagnostics Every hallucinated claim, wrong industry, wrong product, wrong pricing, wrong capabilities, directly impacts trust. NeuroRank™ identifies:
- Factual drift
- Outdated recall
- Competitor substitution
- Negative skew and bias amplification
This is critical for regulated industries, public companies, and brands preparing for listing.
3. Structured Authority Assessment AI assistants depend on machine-readable authority. NeuroRank™ assesses:
- Schema completeness
- Product content structure
- Documentation clarity
- Third-party citation pathways
- Alignment between product, marketing, and documentation surfaces
Weak authority signals lead to omission, invisibility, and unstable recall.
4. Category Narrative Alignment Models define categories differently than search engines. NeuroRank™ analyses:
- How your category is interpreted
- Which players models prioritise
- Where your brand stands in the reconstructed market narrative
This reveals whether the model places you correctly in the category you believe you compete in.
5. GEO Governance Blueprint NeuroRank™ concludes with a 30-90 day governance plan that aligns:
- Marketing
- Product
- SEO
- Documentation
- Data governance
This ensures visibility improvement compounds rather than decays.
Why CMOs Prefer the NeuroRank™ Framework
- It provides quantifiable visibility metrics where none previously existed.
- It connects AI recall directly to pipeline impact.
- It delivers board-ready risk insight supported by hard data.
- It creates a repeatable enterprise governance model for AI-era brand control.
NeuroRank™ replaces SEO guesswork with structured, model-led clarity. CMOs use it to defend demand, restore accuracy, and strengthen competitive advantage in a landscape where AI, not websites, shapes perception.
What NeuroRank™ Reveals About AI‑Era Visibility
NeuroRank™ is engineered to quantify how models interpret, trust, and recall enterprise brands. The system evaluates:
- Inclusion and absence patterns
- Cross‑model variability
- Sentiment polarity
- Hallucination events
- Authority gaps
- Schema, data structure, and narrative alignment
The audits confirm that AI recollection is uneven, fragile, and highly dependent on machine‑readable trust signals. Without governance, visibility decays.
How GEO Reshapes Pipeline, Category Leadership, and GTM Design
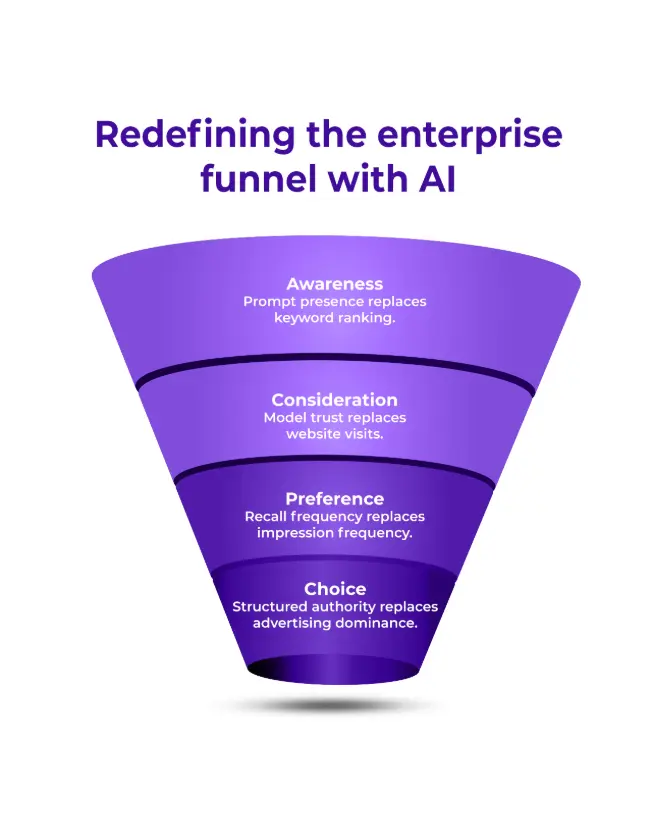
GTM strategies must realign around AI‑first discovery and multi‑model governance.
Industry Implications
BFSI: Compliance and product accuracy must be machine‑readable to avoid misclassification in AI responses.
Healthcare and Pharma: Factual precision is critical. Even minor hallucinations impact regulatory visibility.
Retail and FMCG: Sentiment overweighting and negative skew directly influence consideration and conversion.
Tech and SaaS: Category definitions are being rewritten by models, not analysts.
Energy and Infrastructure: Legacy documentation formats create dangerous recall gaps.
Listed and Pre‑Listing Companies: AI visibility is now directly tied to market perception. Inconsistent naming, factual drift, or outdated public disclosures inside AI answers can influence investor confidence, analyst narratives, and perceived governance quality during listing or pre‑IPO stages.
Across all sectors, AI‑era visibility has become foundational to demand, trust, and competitive advantage. For CROs and Channel Leaders, this is directly tied to deal velocity, partner enablement, and win rates.
What Organisations Must Do in the Next 90 Days
How CMOs Should Brief Their Teams
1. Establish AI visibility as a KPI.
Every brand team must own prompt‑presence metrics alongside traditional funnel metrics.
2. Align product, content, and documentation teams.
Most hallucinations come from inconsistent product narratives across surfaces.
3. Introduce structured content reviews.
Every content asset should pass an AI‑readability check.
4. Build a cross‑discipline GEO pod.
Marketing, product, SEO, documentation, and governance must review AI visibility weekly.
5. Mandate a quarterly AI recall audit.
LLM behaviours change frequently. Visibility without governance decays fast.
Comparison Table: Traditional SEO vs AI Search Visibility Factors
| Capability | Traditional SEO | AI Search (LLM SEO) |
| Discovery Logic | Crawl + Index | Recall + Trust |
| Ranking Basis | Keywords, backlinks | Structured data, citations |
| Sentiment Influence | Balanced | Strong negative bias |
| Data Consumption | Full website | Only structured, trusted surfaces |
| Visibility Risk | Low once ranked | High without continuous recall |
| Competitive Moat | Difficult to shift | First‑mover advantage compounds |
| Governance | Marketing‑only | Enterprise‑wide AI governance |
Case Study: SaaS Brand Reclaims Visibility in 30 Days
A mid‑market SaaS provider faced a visibility collapse across ChatGPT, Gemini, and Perplexity. Despite ranking in the top three SEO positions for 40 commercial keywords, they were absent from AI‑generated shortlists.
NeuroRank™ identified three core issues:
- Missing structured data for key product lines
- Weak citation graph across trusted ecosystems
- Hallucinations confusing their product with a competitor’s capabilities
Within 30 days:
- Prompt inclusion increased by 9x
- Hallucinations dropped by 75 percent
- Gemini and ChatGPT began citing the brand in category comparisons
This shift restored their presence in high‑intent buying moments and improved pipeline velocity.
Conclusion: Visibility Is Now a Trust Contract, Not a Ranking Outcome
AI has become the first interpreter of enterprise brands. Its summaries shape procurement shortlists, partner evaluations, analyst reviews, and investor narratives.
Brands cannot afford to be:
- Uncited
- Misrepresented
- Replaced
- Forgotten
GEO is now brand defence, demand generation, and category leadership rolled into one. Enterprise tech firms that invest early will own the competitive narrative inside AI search.
Key Takeaways
- AI search is reshaping enterprise demand at scale.
- Visibility is now determined by recall, not ranking.
- Traditional SEO cannot measure or fix AI‑era visibility gaps.
- NeuroRank™’s data shows systemic omission, negative skew, and hallucination risk.
- GEO requires structured content, authoritative citations, and cross‑functional governance.
- Early movers enjoy compounding competitive advantage.
Download the Research + Begin Your GEO Transformation
Download the GEO Benchmark Index 2025 to review the full findings from 408000 real prompt simulations, 350 cross‑industry brands, and 70 enterprise GEO audits. Understand exactly how AI models recall, distort, or omit brands in your category.
Request a NeuroRank™ AI Visibility Audit to benchmark your brand’s inclusion score, hallucination exposure, sentiment balance, and cross‑model consistency against enterprise peers. This is the fastest path to repairing visibility, strengthening trust signals, and entering AI‑first consideration journeys.







